


The Main Line Pattern
A Pattern for Integrating Code Quickly

I’ve been reworking some of the patterns from Software Configuration Management Patterns to put them in context and make their relevance to CI/CD clearer. I’d welcome comments on both the form and content. I think that patterns and the pattern form work well from showing the dependencies between different design decisions, though some forms can appear a bit contrived. There is also a version of this pattern on Medium.
Main Line
When you use an agile software development process like Scrum or XP, you can plan iteratively and follow certain practices, such as TDD and CI, to keep code agile, and yet you may still discover that your codeline process doesn’t support your agile delivery model. This pattern describes the high-level structure — a Main Line — that makes it easier to deploy code quickly to enable business value while maintaining stability and traceability by providing a central integration point for code.

Challenges of Balancing Speed and Stability
Stability and speed can appear to be at odds. There is a natural tendency to reduce the risk of error by slow, disciplined steps when integrating work into a code line destined for delivery. For example, the steps one takes before merging changes may include:
More manual testing
More peer reviews
Intricate integration testing
Strict approval gates to prevent ‘accidental’ integration.
All these elements can add some value—testing and feedback can find errors, and finding errors sooner reduces their impact and makes them easier to fix. However, the longer these steps take, the longer it takes to test a change in the context of the integrated code line. The longer work stays isolated, the greater the risk of merge conflicts and divergent design decisions. The sum of the delays also means that features take longer to be released, subjecting you to business risk.
To make it easier to have working code that contains all recent changes that can be tested, some teams choose to use staging branches when work in progress is integrated into a “Develop” branch, which is considered a working branch. (There are variations of this)

Code moves more quickly from the developer’s workspace to the development branch, though, sometimes even that integration cycle is slow because of
The time it takes to go through the various gates, for example, review delays.
Each merge has its own set of gates.
The integration process doesn’t prioritize speed.
Keeping work on isolated branches preserves the stability of the eventual target branch but defers the problem: the target branch receives changes slowly, leading to process and business risk:
Process risk in that less frequent integration can lead to more complex merges, not to mention the inherent complexity of the flow and the number of active contexts a developer needs to maintain.
Business risk because slower delivery of code means less value, and also spending more time budding features before they are validated as useful by end users.
The tendency to move slowly has a feedback effect: A slow integration process leads to a temptation to integrate larger, more complex units of work. But the longer you keep your changes isolated, the harder the integration will be, both for your work and work started after your work stream started. The more overhead for a merge, such as more testing due to change set size, the greater the temptation to introduce more work before you merge.
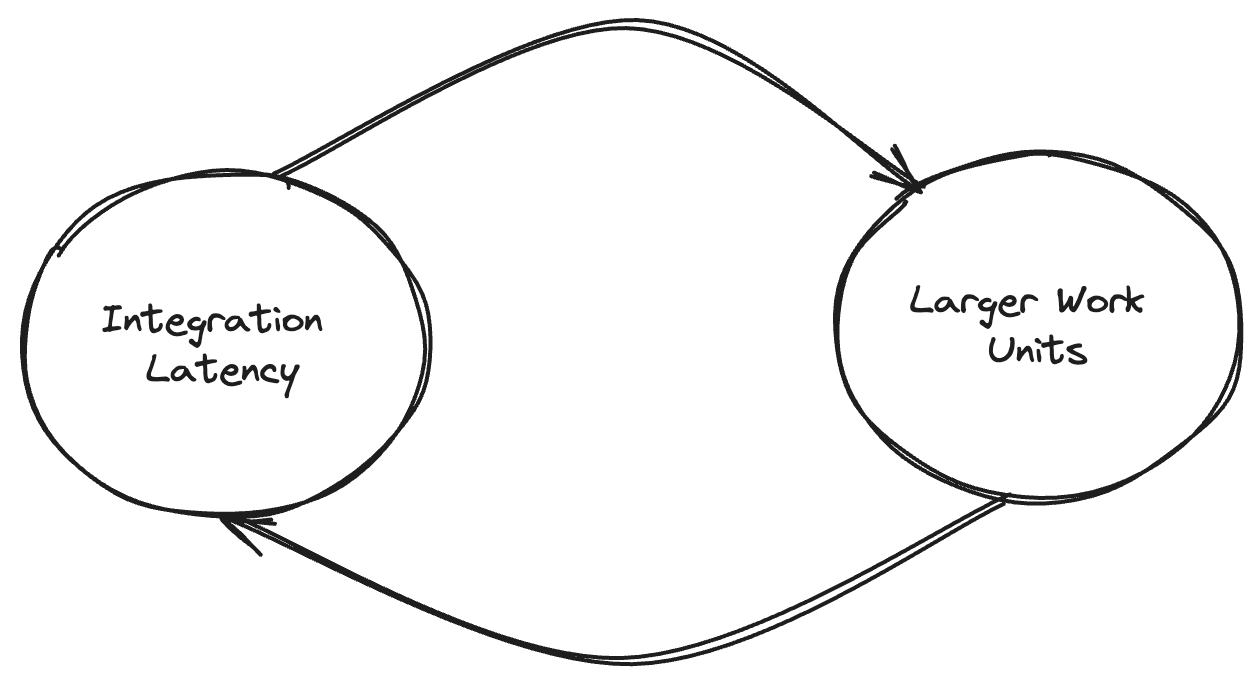
Faster integration means you could miss an error, but slow integration doesn't guarantee perfect software. Regardless of the size of the unit of work or how quickly you integrate it, merging code that breaks the shared integration codeline will slow down the entire team.
Frequent integration is more productive; the more frequently you integrate the simpler each integration will be, and the more likely any new work streams will start with the latest work. (Cite Accelerate)
Create a Stable Baseline
Work on a Main Line, where all work is integrated. Use mechanisms to allow for work to be integrated frequently while maintaining stability so that the Main Line is potentially deployable.
A Main Line is a code line that contains the “record” of the latest work, and its purpose is to track the current state of working code and be the source of all deployments. It is never deleted and lives through the entire project, during which the entire team contributes to it. All work starts from it, all code that will be delivered ends it, and it is the origin of any release (with the rare exception of emergency patch releases).

Maintaining an active, healthy, Main Line takes some discipline. An occasional error is inevitable, so while you might feel comfortable eliminating intermediate branches and getting code to the Main Line quickly, you may be tempted to add extra gates between “merged to main” and “released.” While this might be a reasonable starting place, you want to work to get to a point where the merge to main is quick, automated, and gives you high confidence.
Next Steps
While the Main Line model’s simplicity, with fewer codelines, has advantages, you need some mechanisms to allow frequent integration to happen safely and reliably. You can’t avoid all errors, but you can avoid major ones and reduce the impact of any that slip through.
To help ensure a healthy Main Line you need to:
Define the rules for integrating to the Main Line and when to use other codelines: Codeline Policy.
Provide a place to reliably do development with the correct dependencies and tools: Developer Workspace
Allow for delivery of critical fixes to released code: Release Line
Enable Parallel, Independent Work that can be integrated into the Main Line quickly and reliably: Task Branch
Get feedback on work before it’s integrated into the Main Line: Code Review
Build and Test automatically: Integration Build
Get Feedback on design and implementation: Pull Request
Create a Restrospective Culture that is robust in the face of the inevitability that things will break despite best efforts and has a continuous improvement mindset.
Migrating to a Mainline from other models
The end state of the Main Line model is continuous deployment once code is merged to main. While many teams embrace “Continuous Integration” to the Main Line, continuous deployment from the main line to production can take a few step to get there:
It can present operational risks in terms of setting customer expectations.
Your automated testing process might not give you the confidence to deploy to production without human intervention.
A reasonable migration path is:
Work towards using short lived Task Branches that start from the Main Line and merge to the Main Line
Develop an automated Continuous Deployment mechanisms, starting with deploying to a pre-production environment with each merge to the Main Line.
Over time reduce the time between the CD deploy and the production deployment.
This Pattern Language guides you through the steps in detail,
> minimal branching approach!
I really like this. Most don’t agree that cloning master/main locally results in a local branch of the remote repository
Unless we all share a git repo on the LAN, we are all using branching with git